Probing of Contextualized Embedding
WHAT DO YOU LEARN FROM CONTEXT? PROBING FOR SENTENCE STRUCTURE IN CONTEXTUALIZED WORD REPRESENTATION
AIM
Investigate how word-level contextual representations encode sentence structure across a range of syntactic, semantic, local, and long-range phenomena.
EDGE PROBING
Based on recent token-level probing work, Paper introduce a novel edge probing task design and construct a broad suite of sub-sentence task taken from traditional NLP pipeline.
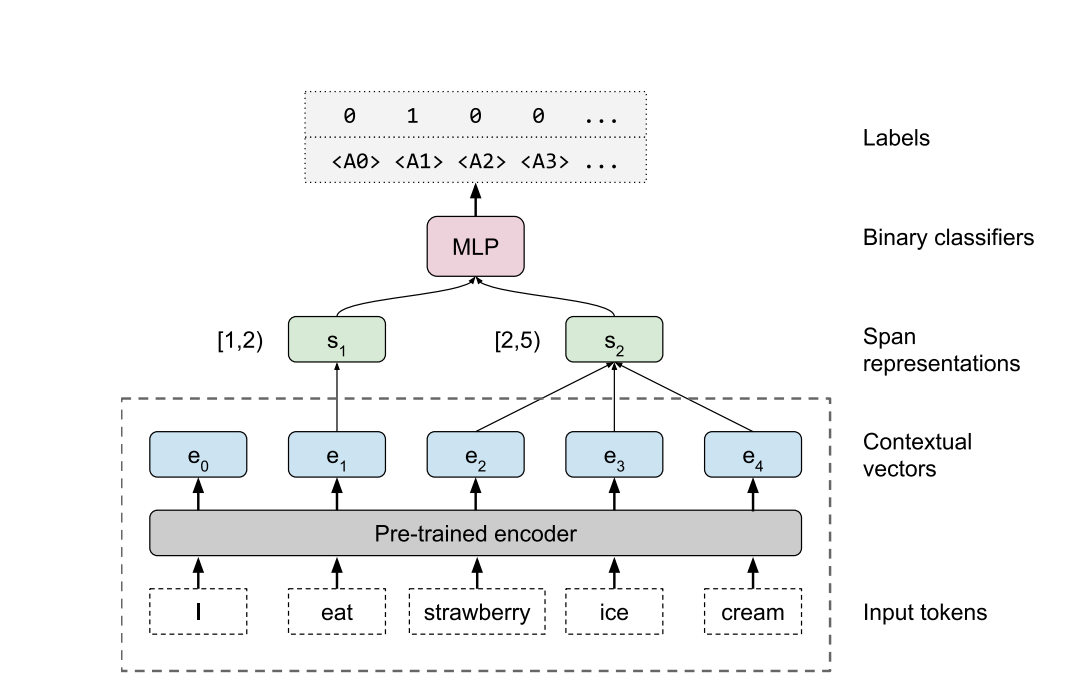
All parameters inside the dashed line are fixed, while we train the span pooling and MLP classifiers to extract information from the contextual vectors. The example shown is for semantic role labeling, where \(s^{(1)}\) = [1, 2) corresponds to the predicate(“eat”), while \(s^{(2)}\) = [2, 5) is the argument (“strawberry ice cream”), and we predict label A1 as positive and others as negative. For entity and constituent labeling, only a single span is used.
Formulation
Sentence as a list of tokens \(T = [t_0, t_1,...., t_n]\), and
Labeled edge as {\({ s^{(1)}, s^{(2)},L}\)}.
we treat \(s^{(1)} = [i^{(1)},j^{(1)}]\) and, optionally, \(s^{(2)} = [i^{(2)},j^{(2)}]\) as spans.
L to be a set of zero or more targets from a task-specific label set.
example:- The important thing about Disney is that it is a global \([brand]_1\)
span or \(s^{(1)}\) = [brand], Label = NN (Noun)
Matric used binary \(F1\) score
TASK:-
- POS : \(s_1 = [i,i+1]\) , a single token and L = (POS)
- Constitutent labeling : span a noun pharse \(s_1 = [i,j)\) ,be a known constituent
- Dependency labeling
- Named entity labeling
- Semantic role labeling (SRL)
- Coreference
- Semantic proto-role(SPR)
- Relation Classification
PROBING MODEL:
Contextual embedding Vector and Integer spans as inputs, and Projection layer followed by the self-attention pooling operator of Lee et al. (2017) to compute fixed-length span representations. Pooling is only within the bound of a span.
Now Span representation is fed into a two-layer MLP followed by sigmoid output layer.
Training by minimizing binary cross-entropy agianst the target label set L
Model - used four recent Contextual encoder mdoels: CoVe, ELMo, OpenAI GPT, and BERT
How to get input embedding for Egde probing models ?
For CoVe, and ELMo, we are going to input embedding obtain by models directly and
For BERT and GPT (because of subword embedding) , Two methods for yielding contextual vectord for each token:
-
cat, where we concatenate the subword embedding with the activations of the top layer
-
mix where we take a linear combination of layer activations (including embeddings) using learned task-specific scalars
Experiment
Lexical Baseline - train directly on the most closely related context-independent word
Randomized ELMo- intialising weights of ELMo randomly
Word-Level CNN- extended lexical baseline by introducing a fixed-width convolutional layer on top of word respesentation.
Results
Encoding of syntatic vs semantic information
Relevant information being contained in intermediate layers implies top layers may be overly specialized to perform next-word prediction.
Contextual representation is strictly more expressive, since it includes access to the lexical representations either by concatenation or by scalar mixing.
larest gains on tasks which are considered to be largerly synatactic, such as dependency and constituent labeling, and smaller gains on tasks which aee considered to require more semantic reasoning, such as SPR and Winograd.
Effect of Architecture
Orthonormal encoder improves significantly on the lexical baseline,but that overall the learned weights account for over 70% of the improvements from full ELMo.**
Encoding non local context
ELMO encoder propagates a large amount of information about constituent, most of it is local in nature.
ELMo improvements it does bring are laregly due to long-range information